Looking for new posts? Head over to my new blog at https://bjcant.dev
At the end of its unit in object-oriented (OO) ruby, the Flatiron school introduces a final project challenging us to create an application that scrapes information from a website and present it in the form of a command line interface, or CLI. About a week before I began the project, Flatiron removed the requirement to publish the program as a ruby gem. I opted to publish my gem anyway. Why not give others the oppportunity to enjoy the thing I worked so hard to make?
TopBeers CLI App
The application I created scrapes the data from Beer Advocate’s Top 250 Beers List, then presents each beer in a list, along with the corresponding brewery and style.

The user can select a beer by inputting the number on the list to find out more details. It is also possible to see a list of breweries and beer styles, and the beers that belong therein.
This app was a great opportunity to stretch my OO muscles while working on subject matter that I love…BEER!
Web Scraping
Web scraping is the practice of programmatically extracting data from websites. Scraping generally involves making an http request, then locating and organizing text by seeking out its containing html elements and css properties, classes, and IDs.
For my app, scraping was required to obtain the initial beer information from the Top 250 list, then again from the detail page of each beer. To do this, I needed the help of the ruby gem Nokogiri and the Ruby module OpenURI. OpenURI is simple enough; it is mainly used to open urls with open("http://websitename.com").
Nokogiri parses HTML and allows for quick and easy document searching. This is generally executed in two steps: document parsring, then searching. Let’s take a look at how this was executed for TopBeers.
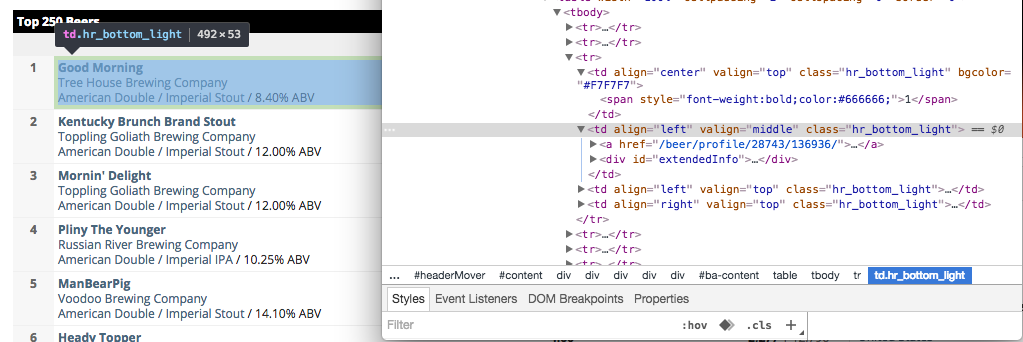
Using Google Chrome’s browser inspector, we see that the <td> element containing all of the information we want (beer name, brewery, style and ABV) has a class of .hr_bottom_light. Unfortunately, in this case the class assignment alone is not enough to specify which element we want. To hone in on those containers with the beer information, we will include the align="left" property.
This is all we need to create an array of objects that contain all of the pertinent information. Later, that information will be organized in Beer, Brewery, and Style Classes.
Here is my .scrap_beers class method inside the TopBeers::Scraper class:
def self.scrape_beers
doc = Nokogiri::HTML(open("https://www.beeradvocate.com/lists/top/")) #makes the http request and loads the html file
beers = doc.search(".hr_bottom_light[@align='left']") #searches by class and align property, assigns all objects to an array
self.create_beers(beers)
beers
end
See the self.create_beers(beers) method call? That is where we operate on our new array of objects! This method iterates over the beers array and creates a new instance of the TopBeers::Beer class, assigning the data within each array element to instance variables of the class instances (how many times can you say ‘instance’ in one sentence?). It looks like this:
def self.create_beers(beers)
beers.pop
i = 0
beers.each do |beer|
if i.even?
new_beer = TopBeers::Beer.new(beer.css("b").text)
new_beer.url = beer.children[0].attributes['href'].value
new_beer.brewery = "#{beer.css("#extendedInfo a")[0].text}"
new_beer.style = beer.css("#extendedInfo a")[1].text
if beer.css("#extendedInfo").children[3] != nil
new_beer.abv = beer.css("#extendedInfo").children[3].text[3, 10].chomp(" ABV")
end
end
i += 1
end
end
So, for each beer iteration we see more Nokogiri searching to find the relevant text. A couple things to note:
See the beer.pop at the top? For some reason the last element of the list is full of some bad characters. This method call deletes it. And the if i.even? check resolves another little bump in the Nokogiri parse: it turns out that only the even-numbered elements in the beer array contain relevant information.
Unfortunately, poorly organized websites can make web scraping difficult. As great as Nokogiri is, it can only get you so far. Websites that don’t readily use class and ID assignments require some clever workarounds to get the right information. This was the case for the Beer Advocate site.
Scraping the details pages for each beer requires some fancy footwork.
def self.scrape_details(beer)
doc = Nokogiri::HTML(open("https://www.beeradvocate.com"+beer.url))
beer.ba_score = doc.search(".ba-score").text
beer.brewery.location_1 = "#{doc.search('.break')[1].children[15].text}"
if beer.brewery.location_1 == "Belgium"
beer.availability = doc.search(".break")[1].children[35].text.strip
beer.brewery.website = "#{doc.search(".break")[1].children[17].text}"
beer.description = doc.search(".break")[1].children[42].text.gsub(/\n\t\t/, '')
else
beer.availability = doc.search(".break")[1].children[37].text.strip
beer.description = doc.search(".break")[1].children[44].text.gsub(/\n\t\t/, '')
beer.brewery.location_2 = "#{doc.search(".break")[1].children[17].text}"
beer.brewery.website = "#{doc.search('.break')[1].children[19].text}"
end
end
I promise it’s not usually this confusing!
Object Orientation
While working on this project, I learned the value of planning and building object relationships before writing any code. Figuring the belongs-to and has-many relationships from the beginning made the programming process quick and easy. I’m going to break it down here:
Classes: TopBeers::Beer, TopBeers::Brewery, TopBeers::Style, TopBeers::Scraper, TopBeers::CLI
The Scraper class has already been defined. It contains all of the methods related to scraping and organizing website information. The CLI class is also pretty straightforward. It contains all methods related to user-interaction. Let’s focus on the other three.
TopBeers::Beer
Class Variable: @@all Contains all instances of Beer
Instance Variables: @name, @style, @abv, @brewery, @url, @ba_score, @availability, @description
Relationships: A Beer instance belongs to a Brewery instance and a Style instance
TopBeers::Brewery
Class Variable: @@all Contains all instances of Brewery
Instance Variables: @name, @location_1, @location_2, @website, @beers
Relationships: A Brewery instance has many Beer instances
TopBeers::Style
Class Variable: @@all Contains all instances of Style
Instance Variables: @name, @beers
Relationships: A Style instance has many Beer instances
All of this planning helped dictate the necessary class and instance methods to get the relationships working properly. Think big picture first, then the details. It helps!
Publishing the Gem
It turns out that publishing a ruby gem is really easy. The tricky part is doing it right. I’d like to share a few tips that will keep you from pushing 5 different versions of your gem within a few hours (like I did).
- Thoroughly test your app and check for bugs. It’s even better if someone else tries it
- Go through your gemspec file and make sure that all of your information is updated
- In your gemspec description, include basic information to get the app up and running
- Separate your runtime dependencies and development dependencies. Runtime dependencies are necessary for your gem to operate
- Make sure your README.md is up to date
In case you do accidentally push a broken version of your gem, the gem yank command is your friend!
Here is a quick video of TopBeers CLI App in action!
See the source code for TopBeers here